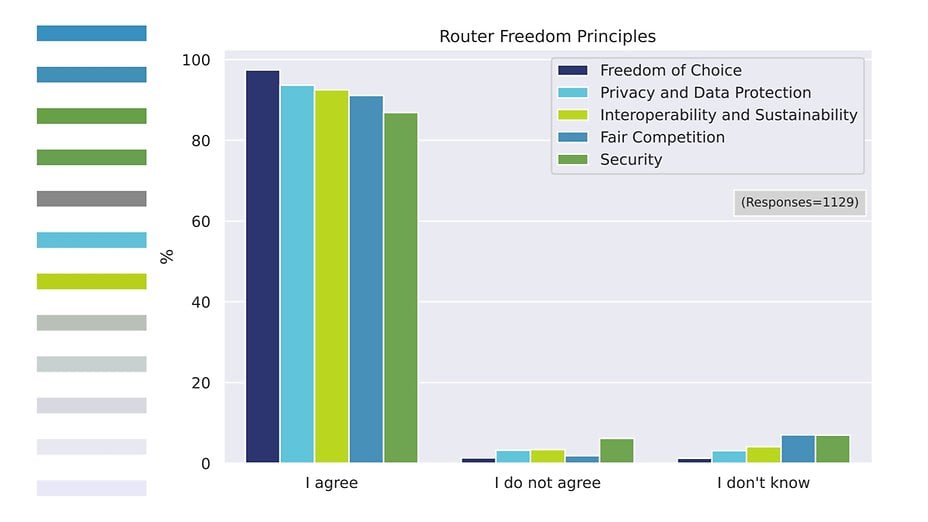
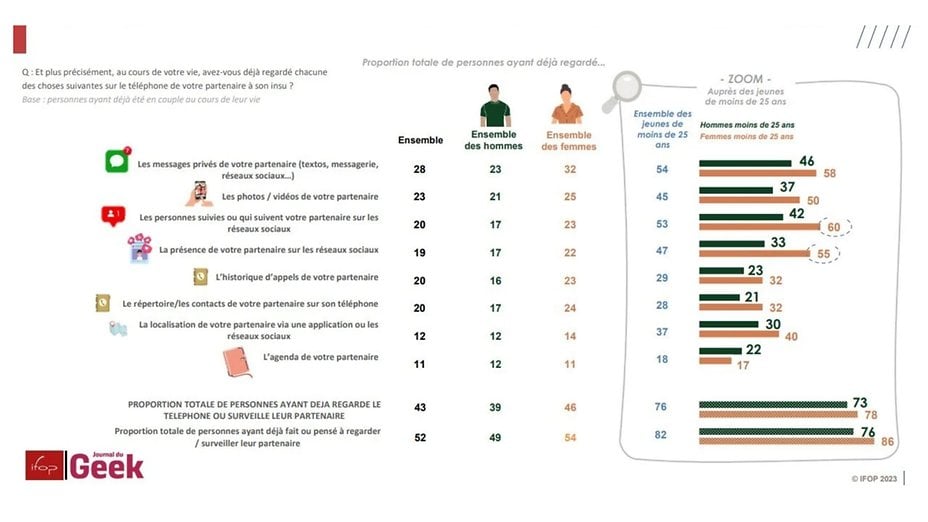
Il est apparu très récemment que Google volait secrètement tout ce qui avait été créé et partagé sur Internet par des centaines de millions d'Américains. Google a pris toutes nos informations personnelles et professionnelles, nos travaux créatifs et rédigés, nos photographies et même nos e-mails - la quasi-totalité de notre empreinte numérique - et les utilise pour créer des produits commerciaux d'intelligence artificielle ("IA") comme "Bard", le chatbot que Google a récemment lancé pour concurrencer le « ChatGPT » d'OpenAI. Pendant des années, Google a récolté ces données en secret, sans préavis ni consentement de quiconque.
Ce vol massif d'informations personnelles a stupéfié les internautes du monde entier, mais Google n'est pas le seul mauvais acteur de la nouvelle économie de l'IA. Selon les termes de la FTC, l'ensemble de l'industrie technologique "sprinte pour faire de même", c'est-à-dire pour aspirer autant de données qu'elle peut trouver. En effet, les grands modèles de langage sur lesquels s'exécutent les produits d'IA dépendent de la consommation de quantités massives de données pour "former" l'IA. Sans cela, les produits d'IA seraient sans valeur.
Les données personnelles de toutes sortes, en particulier les données de conversation entre humains, sont essentielles au processus de formation à l'IA. C'est ainsi que des produits comme Bard développent des capacités de communication humaines. Les œuvres créatives et expressives sont tout aussi précieuses car c'est ainsi que les produits d'IA apprennent à "créer" de l'art.
La FTC a lancé un avertissement sévère à l'industrie de l'IA le mois dernier concernant ce sprint soudain pour collecter autant de données de formation qu'elle peut en trouver*: "L'apprentissage automatique n'est pas une excuse pour enfreindre la loi... Les données que vous utilisez pour améliorer vos algorithmes doivent être légalement collectées. … les entreprises feraient bien de tenir compte de cette leçon".
Plutôt que de tenir compte de l'avertissement de la FTC et d'arrêter son vol de données qui dure depuis des années, Google a choisi de "mettre à jour" discrètement sa politique de confidentialité en ligne la semaine dernière pour renforcer sa position selon laquelle l'entreprise peut tout prendre sur Internet à des fins privées et commerciales, y compris pour créer et améliorer des produits d'IA comme Bard.
Il s'agissait de la première reconnaissance publique par l'entreprise de ce qu'elle faisait en secret depuis des années*: récupérer l'intégralité d'Internet pour prendre tout ce qu'elle pouvait, qu'elle ait contribué ou non aux plateformes Google, et sans tenir compte de la vie privée, de la propriété et de la protection des consommateurs. les centaines de millions d'Américains qui ont partagé leurs idées, leurs talents, leurs œuvres d'art, leurs données, leurs informations personnellement identifiables, etc., à des fins spécifiques, dont aucune n'était de former de grands modèles de langage au profit de Google tout en mettant le monde en péril avec des outils non testés et produits IA volatils.
L'avertissement et l'aveu soudains de Google concernant ses pratiques de scrapping sont intervenus trois jours après qu'OpenAI a été poursuivi pour vol et détournement commercial de données personnelles sur Internet dans le cadre de sa propre opération massive de scrapping, également effectuée en secret, sans préavis ni consentement de quiconque dont des renseignements personnels ont été recueillis. Et bien que l'admission de Google ait été discrète, la réaction du public a été tout sauf cela. Les gens étaient en colère d'apprendre qu'ils étaient, en fait, et comme l'a dit un commentateur, la "sauce spéciale" qui faisait fonctionner les produits Bard et AI comme ça. L'indignation avait un sens. Même si Google avait déjà piétiné le droit à la vie privée, déclarer la propriété de tout et n'importe quoi sur Internet semblait particulièrement audacieux et violent, car c'est le cas.